Since being given the assignment, the young man had encountered serious roadblocks. His first question was how MTBF was being calculated in the oil refining industry. He advised that some people just take the number of months in service and divide by the number of repairs during that time; while others apparently perform a Weibull analysis. The Weibull analysis sounded much more accurate to him, but he wanted to stay with industry standards.
He ran into a second roadblock when attempting to define what a failure is. The refinery was currently contemplating a definition of "anything costing over $1,000", but he wanted to know what the standard was. Using the all-pervasive and now rather customary (and generally inadequate!) Internet search method, he found many articles that talked about MTBF studies. He did not, however, uncover any articles that shed useful light on how such studies were to be set up. Finally, he asked for help in finding some of the answers.
No Standard, Just Choices
There is no written standard on MTBF, but McKenna and Oliverson's "Glossary of Reliability and Maintenance Terms" (ISBN 0-88415-360-6) neatly defines it as:
"A basic measure of reliability for repairable items; the mean life during which all parts perform within their specified limits, during a particular measurement interval under stated conditions; an index of reliability calculated by dividing the total number of stoppages (outages) by operating time; the number of hours or cycles an item or items operated divided by the number of failures that occurred; commonly expressed as a six or 12 month rolling average; also expressed as one over the failure rate."
That pretty much explains what is common practice. By deviating from common practice, perhaps doing a Weibull plot, one achieves another benchmark. A Weibull plot is a reliability prediction technique used to evaluate the reliability parameters of components (e.g. bearings), and the data from it is more precise than MTBF calculations. These plots are also valuable during the development phase of a component. While Weibull plots are possible for failed pumps, the specialist using them will give up the straightforward comparison with others that use MTBF. That should be a concern for us.
More About Weibull For definitions of failures/metrics, etc., go to Paul Barringer's reading list for reliability1. Select an old document, MIL-STD-721. This is one of many military documents Paul has accumulated on his website. Specifically, go to page 11 for the words, which he has reduced to the equations below:

The MIL-STD-721 document reaches way back to the 1970's, and has now become obsolete. Better modern documents such as MIL-HDBK-338 are available today.
Quoting Paul Barringer, "The practice of summing the life of active units plus dormant units is a poor (lazy) engineering practice in calculating MTBF & MTTF metrics. It is poor because it overstates the results by including so-called life of dormant units. This sets a trap for naive people building RAM models of system performance because the flawed metrics will overstate system performance."
The military documents, such as DoD Ram Guide, RAM primer, MIL-STD-785, NASA-Std 8729.1, and other documents listed on the Barringer website, provide some excellent guides for building RAM models.
For Weibull analysis of components:

Here, h is the characteristic life (i.e., the life at 63.2% of the cumulative distribution function, as this is a mathematical property of the distribution--in short, it's the single point representation of durability that you discuss without all of the if/and/buts). The b is the shape factor. For components, b tells you how things died (i.e., b<1 infers infant mortality, b~1 infers chance failures, and b>1 infers wear-out failure modes)--it is important to let the data speak rather than pontificating about how things died.
The term G(1+1/b) is called the Gamma function. For b = 0.5 the Gamma function is 2, for b = 1 the Gamma function is 1, and for b>1 it may be as small as 0.87 or as large as 1, so as a rough rule of thumb, the MTTF is roughly equal to h. You need to know the beta values to get the correct medicine because everyone will tell you things wear out, although, unfortunately, we kill more things than ever live long enough to wear out. (Note: On another website2, Dr. Robert Abernethy provides additional insight into the differences between MTBF and MTTF. Consulting his website may be important for students of the Weibull method.)
MIL-HDBK-338 on page 46 gives you a simple and clear definition of failure: "The event, or inoperable state, in which any item or part of an item does not, or would not, perform as previously specified." Reliability (lack of failures) always terminates in a failure (loss of the function when you needed it). Many other details about failures are also included in pages 46-47.
Finally, download the technical paper #2 from Paul Barringer's website at the bottom of the page called: Where Is My Data For Making Reliability Improvements. It gives other source documents and shows how to make the calculations.
Consider Feedback from an Asset Management Expert
Several comments were also obtained from John S. Mitchell, a self-described "advocate of change" whose "Asset Management Handbook" (ISBN 0-971-7945-1-0) is listed in our essential library3. John believes a meaningful comparison of MTBF must consider the service. Some, because of the fluid and/or operating conditions, will have shorter life expectancies than others. Mitchell uses the analogy of a coal miner who smokes; the miner probably has a shorter lifetime than a non-smoker office worker.
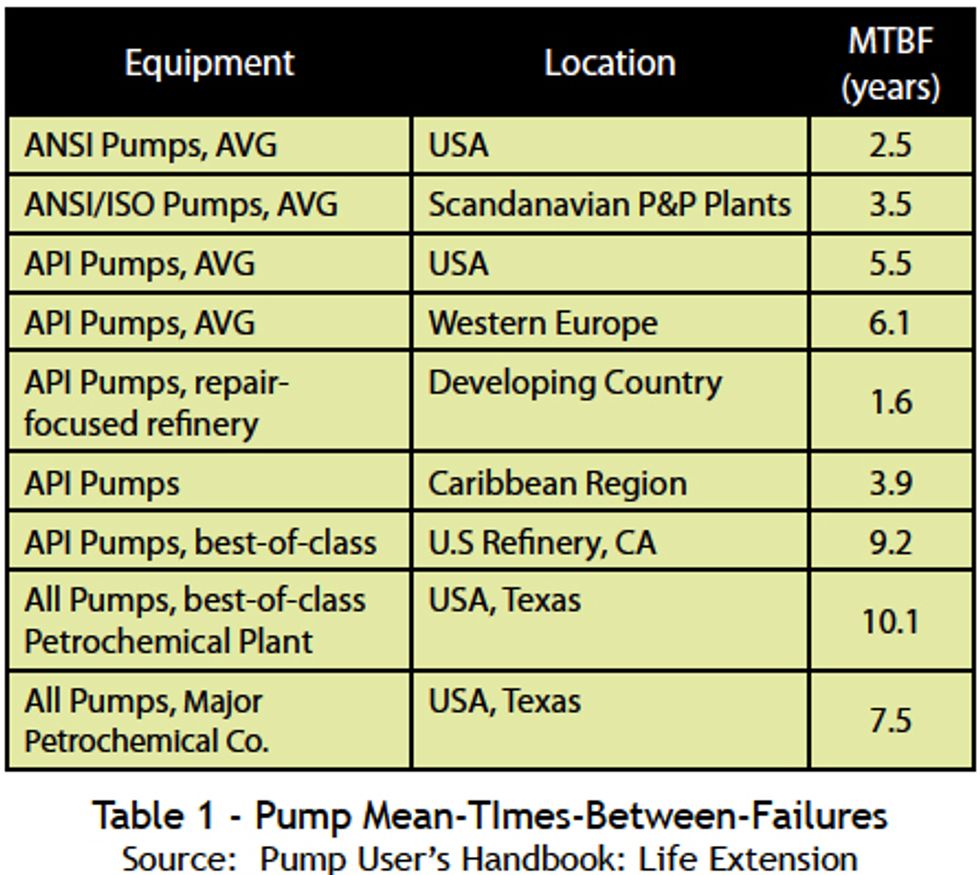
John Mitchell has been trying -- without success so far -- to find a parameter that will, with one number, describe the distribution around an average. Distribution around an average might be the percentage or number of the total population more than 20% below the average MTBF. As an example, suppose a plant reports an MTBF of 48 months. This would be showing performance a bit below best in class in Table 1, from "Pump User's Handbook: Life Extension" (ISBN 0-88173-517-5), but doesn't say much beyond that. Knowing also that 2% of the total population was below 36 months would be useful information because it would tell us that the plant was aware of certain pumps that failed more often than others. (In many refineries that number is somewhere between 7 and 10 percent). However, suppose one found out that the MTBF of 25% - 30% of the population was below 36 months, our diagnosis might be quite different and the opportunities for improvement would be shifting to a new focus.

More Experience-based Advice You Can Use Today
The explanations offered by Paul Barringer and John Mitchell will have to be weighed by serious reliability professionals. Some of their suggestions were certainly considered in the mid- 1970's when we wrote about calculating pump MTBF based on actual operating time. Yet, industry soon decided that the numbers looked better when the calculation encompassed all installed pumps, irrespective of running or not running. Moreover, we have always advocated picking first the ripe, low-hanging fruit and hasten to note that not everyone has heeded this advice. We are where we are and the picture is not rosy. Repeat failures abound and continue to be tolerated. Repeat failures are warning signs; they are the inevitable precursors to extreme failures which very often kill people. To this day, we see CMMS (computerized Maintenance Management Systems) software that allows log entries in words such as "bearing replaced." To be of use to devotees of equipment uptime, a system must recognize that accurate failure analysis is required for failure avoidance. The entries must properly identify why a bearing failed and diligent failure analysis is absolutely necessary. Failure avoidance should be the ultimate goal because it means asset preservation and curtailment of money wasted on repeat repairs, not to mention costly remedial action after an extreme failure. All too often, persistent repeat failures are evidence of seriously flawed reasoning.
The engineering student employed as an intern at that refinery probably would not wish to lose the opportunity for easy tracking of pump failures. He was probably searching for answers to tasks assigned to him by others. We can only speculate that "persons unknown" are often looking for ways to bury the unacceptable performance of their refinery pumps. They would be delighted to obfuscate the issue by arguing over the most precise numerical evaluation. We, for our part, believe the most productive choice to reduce pump failures is to compare one's pump MTBF against other refineries and to itemize and comprehend what "others" do differently. Note that we are not advocating that you compare your refinery against any non-refineries, but you could make a relevant comparison between a given process unit at your refinery against a like process unit at another refinery.
Although such comparisons are usually made on the basis of MTBF, they are still more useful than anything else. They lead to the next and most important step towards implementing the necessary changes, i.e. intelligently upgrading pumps or systems that fail frequently. Typically, and with few exceptions, these changes must be made on pumps with low MTBF. The simple MTBF roadmap has been followed for the past 35 years; its relative success makes us comfortable with the McKenna-Oliverson definition mentioned earlier. In stark contrast, we consider endless debates over more precise or limited definitions both unproductive and all too often diversionary. In this context, debates generally solve nothing, they are mere exercises in bureaucracy. Exploring the failure history of a given pump in a given service in YOUR refinery and then comparing its reliability with that of a pump in the same service at SOMEONE ELSE'S refinery is of real value. It points out the way to lasting improvement.
How to Recognize a Good Pump MTBF
Examining pump repair records (and the admittedly imperfect MTBF metric) is deemed useful for responsible and conscientious pump users. In view of that fact, the preface to the 2006 Pump User's Handbook (ISBN 0-88173-517-5) alludes to pump failure statistics. Again, and for the sake of convenience, these failure statistics are often translated into MTBF. Agreeing with McKenna and Oliverson and because they wanted to avoid arguments on statistics, many of the best practices plants in the time period of the early 2000's simply took all their installed pumps, divided this number by the number of repair incidents, and multiplied it by the time period being observed. For a wellmanaged and reasonably reliability-focused U.S. refinery with 2,400 installed pumps and 312 repair incidents in one year, the MTBF would be (2,400/312) = 7.7 years. The refinery would count as a repair incident the replacement of parts, any parts, regardless of cost. In this instance, a drain plug worth $2.90 or a casing costing $8,000 would show up the same way on the MTBF statistics. Only the replacement of lube oil, a routine maintenance task, would not be counted as a repair.
Using the same bare-bones measurement strategy, and from published data and observations made in the course of performing maintenance effectiveness studies and reliability audits in the late 1990's and early 2000's, the mean-times-between-failures of Table 1 have been estimated. As of 2008, we have reason to believe the figures are valid within a 10% range of accuracy.
It should again be emphasized that many plants are achieving these mean times before a failure occurs. Why, then, the difference between a "best-of-class" U.S. refinery and a somewhat mediocre performer? There are many reasons that account for the difference. An unsuitable seal with a lifetime of just two or three months will have a catastrophic effect on pump MTBF, as would a badly-performing coupling or bearing. A good refinery frowns upon pulling piping towards the nozzle of a fluid machine, a mediocre refinery permits these disastrous procedures to continue for decades. One refinery supports its machine baseplates with epoxy grout, another refinery not only uses an inferior grout system, but might also allow it to soak with oil, degrade, and deteriorate. It is those types of things, and in areas of lube application, bearing housing protection, mechanical seal selection, installation methods and so forth, that the "best-of-class" differ from the weak performers.
What Constitutes a "Failure"
Finally, we were asked what constitutes a failure. In particular, we would like to comment on the sordid implications of limiting the term "failure" to events costing over $1,000.
In "Glossary of Reliability and Maintenance Terms" , McKenna and Oliverson defined a failure as:
"The termination of the ability of a functional unit to perform its required function; loss of function when the function is needed; the event, or inoperable state, in which any item or part of an item does not, or would not, perform as specified; any event that results in work performed on equipment, rather than scheduled preventive or predictive maintenance that requires the equipment to be shut down for repair or whose lack of repair could ultimately lead to an equipment shutdown. Synonym: malfunction."
We are much indebted to Paul Barringer for providing the many links that will facilitate serious research on reliability subjects. The "Essential Reliability Library, 2008" is the author's own recommendation. We consider it rather elementary, but representing a good first step for machinery engineers.
We accept this definition without qualification or reservation, and offer two examples that illustrate why. Years ago, a plant decided to count failures as only pumps that were taken to the shop for repair. One day, a badly mangled pump was being parked on a flatbed trailer near the shop. Because the pump never entered the shop, it did not appear on the failure record kept by this facility. Another plant decided that "rework" should not be counted as a failure. The facility defined as rework any successive event, occurring within three days of repair completion and restart. This plant then counted the second, or third, or fourth event as part of the same repair and made it show up only once on the refinery's failure log. Those were the games we have seen played when industry deviated from the definitions crafted by people with common sense and logic.
So, again answering the intern's question with an example: If an O-ring worth $2.20 allows oil to leak, it must be counted as a failure. If an impeller replacement were to cost $100,000 plus labor, it would also be called a failure. The most crucial issue identified here is the huge problem many refineries have today: It's a people and people-management problem. It's a problem with setting the wrong priorities. An individual tasked with managing equipment reliability must have the time and the motivation to read, to assemble a reference library (see below), to engage in effective root cause failure analysis, and to improve specifications for both new (future) and present (existing) equipment installed at his plant. He must also mentor others, and do so with knowledge and wisdom. If he neglects any of these duties, he should be viewed like a medical doctor lacking in those traits - society would deny him the title MD. Likewise, a mere dabbler in reliability engineering may not deserve to be called a professional. The medical analogy could also be extended to reliability practitioners that feed their minds only on the Internet. Reasonable people would never entrust life and health to a medical doctor whose knowledge was derived solely from the Internet, from its sales-driven advertisers and from conversations with the purveyors of anecdotal knowledge. Needless to say, a medical professional is being taught by other experienced professionals and will consult relevant texts. It should be no different with reliability engineers working in industry.
I have compiled an essential reference library for those who wish increase their knowledge, which can be found at the link listed in Reference 3 below. Rest assured that research via exclusively consulting the Internet will, at best, uncover disjointed pockets of information. The information so found will not follow a logical progression and will not even come close to conveying the coherent picture needed by true professionals.
References
1.Paul Barringer's complete reading list can be found at the following link:
http://www.barringer1.com/read.htm
2.Dr. Bob Abernethy's website:
http://www.bobabernethy.com
3.The Essential Reliability Library 2008, a reading list compiled by Heinz P/ Bloch:
https://reliabilityweb.com/articles/heinz_bloch_recommended_reading_list