"Do you want to be a leader or a lager when the economy turns around?"
Many industries have advanced in the maintenance and reliability in their operation and have taken great strides toward managing asset integrity. By applying known best practices in maintenance and reliability they have found they can optimize asset integrity and reduce total cost along with reducing risk by applying these known practices. However, most organizations are still trapped in the old way of thinking. A great way to know where you stand is to answer these questions:
1. Have your assets been ranked based on criticality?
The definition of critical equipment may vary from organization to organization. In fact, if it is not formalized there may be several interpretations of equipment criticality within a single organization. The assumptions used to assess what equipment is critical are not technically based. As a result, when different individuals are asked to identify their critical equipment, they will likely select different pieces of equipment. Often we are told, "all of our equipment is critical!" Selections are based on individual opinions, lacking consensus. The potential for equipment failure having significant safety, environmental or economic consequences may be overlooked.
A consistent definition for equipment criticality needs to be adopted. The definition used in the context of this document is:
"Critical equipment is that equipment whose failure has the highest potential impact on the business goals of the company"
Each asset is ranked based on environmental impact, customer impact, cost, and more. Remember 20% of your assets utilize 80% of your resources. Criticality ranking is developed by all key function leaders in an organization and their decision impacts which equipment to focus on with a strong maintenance strategy, equipment replacement strategy, PM/PdM Compliance and planned and scheduled maintenance work.
2. Can your measure Mean Time Between Failure (MTBF) of your critical assets?
This is a simple metric of measuring emergency or urgent work orders divided into time. If your maintenance department cannot provide this information in a matter of minutes for the total operation or a critical asset then there are two problems;
• The maintenance software is not being used to its fullest potential, even though you may have spent millions to install and maintain it.
• The maintenance department has not been educated in basic maintenance management principles.
3. Do you have 100% PM Compliance and continue to have equipment breakdown?
Not hard to figure this one out. Take a sample of your current PM inspection sheets and if they do not address specific failure modes and are more quantitative in nature then you have a problem.
4. Are your total maintenance costs going down or are they flat?
If your maintenance cost continues to go up and you are adding staff or contractors you are in what I called "reactive maintenance". Education of best practices and not allowing your maintenance staff and senior leadership to pick and choose which "best practices" they want to apply is the best solution. The maintenance process is like a puzzle; if you want to gain the results of a completed puzzle then all elements must be in place and applied at the right time.
In this presentation we will discuss what are known best practices in Asset Integrity and how they are applied to prepare an organization for the economic turn around.
Let's look at Shell's Asset Integrity and Risk Management Statement:
Asset integrity and process safety standards
We are committed to preventing incidents that put our people, neighbors, the environment and our facilities at risk. Asset integrity and process safety means making sure our facilities are well designed, safely operated and properly maintained.
Webster's Dictionary: Asset Integrity
Asset: anything of value that a corporation owns.
Integrity: firm adherence to a code
"Asset Integrity is anything of value that corporation owns that is held in firm adherence to a code"
The Codes can be defined as ISO, ASQ, etc. The question is to what adherence your company meets of these codes? You can say we meet environmental or safety codes by meeting PM Compliance every month. Is this what the intent of a true PM Program? A preventive maintenance program is to prevent or predict a specific failure mode. All PM Compliance tells us is that the PM is completed within some schedule however it does not tell us if the PM is effective or not. If something is of value to a corporation would not want to ensure it is well protected from failure especially if the failure results in cost.
Let's look at the how this entire asset integrity process works. Asset Integrity impacts safety, cost, and service to the customer. It also impacts your competition. If we look at the Market Survivor Model it tells use a lot.

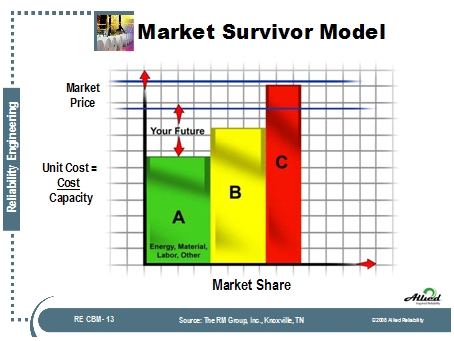
In any company it will own a certain portion of market share. The market price drives profits and your future. With company "A" their market share is high, cost are low, and asset integrity is high thus they are prepared for economic turn around. Company "B" has a large part of market share however their cost is higher than Company "A" and this puts them at some risk. Their asset integrity is not optimized and thus their cost is higher along with risk. Company "C" has the smallest market share and the largest cost. A good example is Alcatel Telecommunications where in 1999 they were Company "C". The Fiber Optic Cable Business was growing at a rapid rate. By assessing the current level of their asset integrity program we found key areas of improvement closed the gap quickly (within 6 months). They went from being a "C" Company to an "A" Company in a short period of time. Their return on investment was 8:1 with 6 months. This involved the application of know best practices in maintenance and reliability. Best practices are measurable and do impact the Customer's need in Quality, Delivery and Price as seen in the chart below.

Some of the known best practices are:
• Manage asset health effectively and efficiently by using the right metrics or Key Performance Indicators (KPIs) such as:
o Mean Time Between Failure: Most companies don't measure mean time between failures (MTBF), even though it's the most basic measurement that quantifies reliability. MTBF is the average time an asset functions before it fails. MTBF should be used for:
- Overall Operation
- Area
- Asset Type
So, why don't they measure MTBF? We will discuss those reasons in this presentation
- % of assets with No Identifiable Defects means you can: Identify a component defect early enough in the failure process where work can be planned and scheduled effectively and without interrupting operations or customers.
In this case everyone must understand the PF Curve and how it impacts the asset reliability.

"P" on the PF Curve is the point at which failure begins on a specific component with will lead to catastrophic failure of an asset. Once a failure begins we call this a defect and the severity of the defect and criticality of the asset determines how quick we respond to the problem. If the defect severity is low and asset criticality is low then there is no panic.
Tracking the percent of assets with "NO Identifiable Defect" is key to knowing the current health of your assets. When the % of Assets with No Identifiable Defect is over 80% there is no longer a need to track Mean Time Between Failure because we are now in a proactive not reactive mode.

An asset that has an identifiable defect is said to be in a condition RED. An asset that does not have an identifiable defect is said to be in condition GREEN. That is it. It is that simple! There are no other "but ifs", "what ifs" or "if then". If there is an identifiable defect the asset is in condition RED. Yellow is an unknown and must be either determined to be Green or Red within 72 hours.
• Applying the right maintenance strategy at the right time means: When an organization is focused on preventing and predicting failure modes they can "Optimize Asset Integrity at an Optimal Cost" along with managing risk associated with all an operation. My question to you is...
"Do you know the failure modes of your critical assets and if so are you applying the right maintenance strategy at the right time?"
An example of a failure mode would be pump bearing failure which could have been caused by poor alignment practices. If someone were following an inspection checklist for alignment they would have found the problem. Proper alignment should identify using Vibration Analysis as the most cost effective maintenance strategy. Vibration Analysis will tell a good analyst if the shafts are in perfect alignment, if a bolt is loose on the motor, if the pump has bearing stress, etc.
"Failure of critical assets is unacceptable as is spending too much money on reliability. The focus should be applying the maintenance strategy which predicts or prevents a failure mode in the most cost effective manner?
• Identifying the Most Dominant Failure Pattern in your operation; Many organizations today are focusing their resources on the most dominant failure pattern in their operation instead of reacting to problems. Identify the most dominant failure pattern allows a company to focus on the common thread which has the largest impact on asset integrity. The US Navy conducted a study of their assets and found the most dominant failure pattern was infant mortality and considered the findings to be unacceptable. They put forth an effort to reduce infant mortality of their assets from over 60% to 6% and were successful in accomplishing it. Focusing on the dominant failure pattern causes an organization to identify the common thread between different types of assets and impacts asset integrity overall in an effective manner. The failure patterns shown below were conducted back in the 1960s by Nolan and Heap with United Airlines. Many companies have found these failure patterns to be same across most industry verticals.

Causes of Infant Mortality has been found to be dominant in most industries and not wear out. Here are a few examples of Infant Mortality:
Number 1: Lack of effective preventive, corrective, lubrication, work procedures.Number 2: No one follows the steps, specification of current procedures because they do not agree with them or are lack leadership follow-up.

Number 2: No one follows the steps, specification of current procedures because they do not agree with them or are lack leadership follow-up.
Number 3: Contamination control - personnel applying grease into a perfectly good bearing with contaminated grease on the end of the lube fitting on the motor or the lube gun.
Number 4: Not removing the relief plug on large motors to relieve oil grease to purge out of the motor. Walk out to a 30-100 HP motor and look for a plug under the motor bearing and see if the plug has ever been removed.

Number 5: Welding on equipment without attaching the ground lead within 6" of the weld. Most construction and maintenance personnel attached the ground for welding as close to the welding machine as possible thus allowing current to flow to the path of least resistance (aluminum conduit, etc.). We do not want arcing between bearings, motor stators, electrical circuits, etc.
"If your welding lead and ground lead on your welding machine (even contractors) is not the same length then you have infant mortality"
The list can go on and on. I think everyone understands the point. If you could reduce the occurrence of this failure pattern by 50% you will make a large impact on asset reliability and cost.
The ultimate goal is to extend the life of the equipment without seeing "P" on the PF Curve by applying Precision Maintenance which includes training craft personnel, effective work procedures, etc. If you look at the I-P Curve below decide which curve your maintenance staff is currently working. This exactly what the US Navy did.

People will say "we do not have infant mortality". I hope after reading these statements above you return to your organization and investigate for yourself. If you like a longer list send me an email and tell them which industry are in and I will share industry specific issues causing infant mortality. The long I-P will never be obtained as long as the focused is not on the reduction of infant mortality by everyone from Project Engineering to Operators.
What Would a Successful Asset Integrity Manager do?
A successful Asset Integrity manager always focuses on providing the reliability to an operation at the rate which its customers demand. We know this is not easy however; many organizations have spent millions of dollars on performing Reliability Centered Maintenance (RCM) on their assets with what seems like very little return on the investment.
Doug Plucknette, a noted RCM expert and author states in his book Reliability Centered Maintenance using RCM BlitzTM, "The key to RCM was abandoning the philosophy of "preserve-equipment" in favor of "preserve-function". Simply put, equipment became the means to an end, not the end in itself". Doug has performed RCM on thousands of assets world wide and is noted among the best in the business.
Past studies have concluded that a maintenance policy based on operating age would have little, if any, impact on failure rates. Thus, applying time-based maintenance on equipment which has no "wear-out" pattern was futile. This forced a change in philosophy from, "It wasn't broke, but we fixed it anyway" to "If it ain't broke, don't fix it".
These studies also concluded that:
- Time-based maintenance works only for a small percentage of components, and then only when there is solid information on their "wear-out" characteristics".

- Condition Based Maintenance (CBM) is the most-preferred option. That means monitoring, observing and taking non-intrusive actions, such as lubricating and cleaning, until a condition signals that corrective action is necessary. This means striking the balance between PM and Condition Monitoring / Predictive Maintenance.

There are facts we know and that is the cost to repair increases the longer we wait and that the time in the x axis on the PF Curve is an unknown and that we can't determine how long that is and when something is going to fail.
"If you hear people say I think it will last a little longer" when a defect has been identified using one of the Condition Monitoring Technologies then you are taking a great risk. You should be using asset criticality and defect severity to determine when to make the repair. Have you ever seen a large pump fail after the bearing defect has been identified 6 months earlier? It is all about risk and the consequence of that risk.

- Run-to-failure is a viable tactic in situations when there is little economic and NO safety or environmental impact.
- In a significant number of situations, the very act of maintenance itself causes subsequent failure of the equipment.
- Non-intrusive maintenance tasks should be used instead of intrusive maintenance whenever possible. In other words, don't do any maintenance, except monitoring and non-intrusive sustaining actions, until condition directs intrusive corrective action.
A simple example is v-belt tension. The PM states "Check tension of Belt". The equipment is stopped and the belt checked and found to be "loose" so the mechanic tensions the belt using his hand as the tension gage. It is highly probable he has over tensioned the belt because if he under-tensioned it you would hear the belt squeal when it returns to full RPMs. Over-tensioning of the belt will cause bearing failure and cause the belt to "creap" causing the RPMs of the driven unit to not be constant. Why not use Infrared Inspection and look for belt slippage while the equipment is running?

V-Belt Slipping Identified with Infrared Technology
You must move from being a PM Centric organization to a truly PdM Centric Organization if you ever want to obtain "Optimal Asset Integrity at Optimal Cost".
In his book, Plant Engineer's Handbook, Keith Mobley links the following benefits to PdM:
- Maintenance costs - down by 50%
- Unexpected failures - reduced by 55%
- Repair and overhaul time - down by 60%
- Spare parts inventory - reduced by 30%
- 30% increase in machinery mean time between failures (MTBF)
- 30% increase in uptime
Now these numbers may seem high. But even if you take only a fraction of these benefits, the financial impact of an effective PdM program at most organizations can easily reach into millions of dollars.
Despite what you may have heard, the foundation of a successful PdM program is a simple list: A detailed, accurate equipment list.
Why? Because your equipment list is the foundation for all of the key steps
that follow. For example, a good list is essential for:
- Identifying how your equipment can fail (identifying failure modes)
- Choosing the right PdM technologies to apply to the asset
- Determining the ideal amount of PdM coverage for your operation
- Ranking the criticality of each piece of equipment
- Building databases for each PdM technology
- Determining PdM staffing levels
So if your list is incomplete or incorrect, everything that's built from it will be flawed. Any shortcuts or inaccuracies will be exposed as big problems later.
Here's a sample of recommended technologies by equipment type for a specified
Environment;

In the last 40 years, no better method than RCM has been found for determining what maintenance should be performed to increase asset integrity. Four statistically significant studies have confirmed the validity of RCM.
In a survey conducted by Reliabilityweb.com in 2005, many companies offered the following excuses for the failure of their Reliability Centered Maintenance Implementations.
"Organizations want results right away, not in 6 months or a year. The classical RCM process is too time and resource intense."
"RCM is a great tool but very resource intensive."
"100% reliability is extremely expensive, difficult to attain, and not necessarily the right answer."
"RCM is misunderstood to be software."
"In the beginning, it was hard. And it is still a challenge to steer the mind-set toward more condition-based maintenance than time-based."
"We always ran into the problem with implementation. In the few places where we implemented it successfully, it was at the maintenance level. And recognition for it was non-existent."
"The system is very strong but too high level ..."
The truth is, there are many pitfalls in RCM. But few get revealed when an RCM project fails. You see, nobody wants to write an article or present a paper at a conference which reveals how money was wasted or about great visions that were never realized.
In order to ensure RCM works in organization one must focus on the systems that will give you the best Return on Investment (ROI).
Simply put, RCM is a slam dunk when it comes to return on investment for critical assets. Begin you RCM effort by identifying the top 10% of your most critical assets. Once this list has been identified, you should now begin to measure Reliability on these assets; performing RCM analysis on those critical assets that have equipment-based operational, speed and throughput losses and thus reducing total cost of maintaining these assets by reducing contractors, overtime, maintenance parts, and fines. If you have selected a critical asset, your implemented RCM maintenance strategy will show measurable improvements with added improvements in Health, Safety and Environmental performance as well.
As a general rule, the success of your first implemented RCM analysis will build the business case to complete RCM analysis on the remainder of your critical assets.
In the simplest terms, RCM is a decision-making process which calls for answers to questions such as:
- What is this system supposed to do?
- How can it fail to do that?
- What causes it to fail?
- What happens when it does fail?
- Can we predict or prevent that from happening?
Getting the Tools in place - Funding, Staffing, Practices, and Reporting
Step 1: Do not accept excuses why you cannot transition an organization to the optimal maintenance model. Steven Covey once stated the following: "Your sphere of influence is very small, your area of concern is very large, focus on your sphere of influence and not on your area of concern and you will find your sphere of influence will grow."
When an organization transitions from their current maintenance model to a more proactive one, you will find staffing is not a problem, cost are lower, and emergencies become a rare occurrence, however, you must take it one step at a time and follow the path others have made. There are no excuses for following the wrong path, best practices are known.
Step 2: Develop a business case for the reliability revolution. Identify cost and return on investment based on known data. Involve senior leadership and the financial team in the business case development. You must have everyone sold on this idea of change or it will never happen. Too many organizations have had many false starts. You should never start a journey without everyone knowing success is the only option.

Step 3: Develop a master plan which focuses on results and moving an organization from being PM to PdM Centric using the Proactive Work Flow Model. In this plan you want financial targets and metrics to ensure you are receiving the benefits expected. You want short term results with long term gains. Note the Work Flow includes Management of Change (MOC) procedures to insure consistency of processes and data. In addition, a process for a Failure Report Analysis and Corrective Active System (FRACAS) is identified for ensuring failure data is analyzed and used for decision making. A master plan should be focused on asset criticality of all assets, focusing on the most critical at first. Implementing known best practices at the right time and not trying "new ideas" which are not proven.
Step 4: Ensure you have identified key performance indicators (KPIs) and financial targets. Make sure you have leading KPIs and lagging KPIs developed which equal the expected financial return on investment (ROI). These metrics and financial targets must be aligned with the process changes being made. In financial targets we want "hard dollar" savings and not "soft dollars. While working at the Pentagon with the US Army I was in a meeting and Lean Six Sigma Director was reporting to his General officer (3 star General) and he stated they he had exceeded their expected goal of $70 Million Dollar savings and the General looked at his comptroller and ask if he had seen the savings and if so he wanted to use this money for a critical project. The comptroller stated he had not seen any monetary savings. Needless to say the General was not happy about this situation. Remember "hard dollar", verifiable savings can only reported.
Here are some known benchmarks:
Benchmarking can be deceiving by it is a great way to know where you stand versus other companies. The metric is the amount of money spent annually maintaining assets, divided by the Replacement Asset Value (RAV) of the assets being maintained, expressed as a percentage. This metric allows one to compare the expenditures for maintenance with other plants of varying size and value, as well as to benchmarks. The RAV as the denominator is used to normalize the measurement given that different plants vary in size and value.

Here is what we know:
Companies who are leaders have an RAV of less than 3.5% for Maintenance
Companies who are in a reactive state have an RAV between 3.6-14%
Where do you stack up? The definition has been defined by the Society for Maintenance and Reliability Professionals (SMRP) after years of research.
Here is SMRP's definition:
Guidelines provide additional information or further clarification on component terms used in SMRP Best Practice Metrics. This guideline is for Replacement Asset Value (RAV).
A. Definition:
The Replacement Asset Value (RAV) is defined as the cost that would be incurred, in today's dollars, to replace the facility and equipment in its current configuration. It is intended to represent the realistic value to replace the existing assets at new value.
B. Purpose:
RAV is used as the denominator in a number of calculations to normalize cost performance of facilities of various sizes within a given industry. These calculations are used to determine the performance of the maintenance and reliability function relative to other facilities within its industry.
C. Inclusions:
• Building envelope
• All physical assets (equipment) that must be maintained on an ongoing basis
• The value of improvements to grounds (provided these must be maintained on an ongoing basis)
• Capitalized engineering costs
D. Exclusions:
• Value of land on which the facility is situated
• The value of working capital:
o Raw material inventory
o Work-in-process inventory
o Finished goods inventory
o Spare parts inventory
• Capitalized interest
• Pre-operational expense
• Investments included in construction of the facility that are not part of the facility assets
• Mine development
Formula:
Annual Maintenance Cost per RAV (%) = Annual Maintenance Cost ($) X 100
Replacement Asset Value ($)
Look at these examples of the cost a company loosing by not following codes and standards identified to optimize asset integrity.

This is not including increase equipment performance and output which can be 2-10 times these losses.
Step 5: Educate everyone from top leadership to operators on your plan and what future state looks like. You want operations to understand they own reliability integrity as an equal partner with maintenance and of course engineering. This is a three legged stool which will fall if not supported properly.
Step 6: Execute the plan and always meet targets and goals set by the plan. Ensure everyone sees the KPIs and financial targets which were established and thus know the "score in the game".
In summary, organization can be successful if they apply known best practices at the right time and tie all changes to "hard savings". Remember the ultimate goal is "optimal asset integrity at optimal cost" by following known "best practices".
If you have questions or comments please post them below.