It illustrates that of 330 accidents in the workplace, 300 will result in no injuries, 29 will result in minor injuries and one will result in a major injury. This is shown graphically in Figure 1.

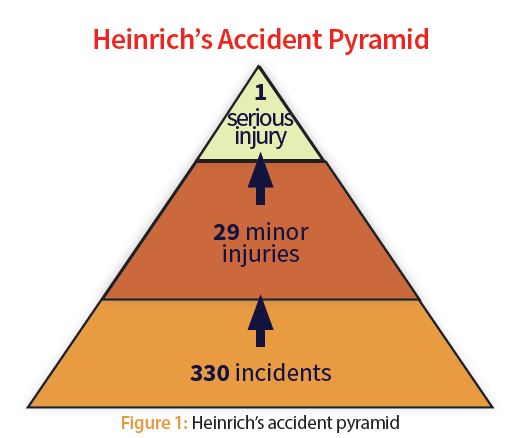
Heinrich is given much credit for bringing safety to the forefront and beginning the process of linking minor accidents to an increased risk of major accidents and injuries. He is also credited with suggesting that people’s unsafe acts cause the vast majority of accidents. But, he was soundly criticized at the time for lack of documentation to back up his theory. Frank Bird did additional work in the 1960s that was much better documented and received. He concluded that for every 600 near misses or minor incidents, you will have some 30 incidents or accidents resulting in 10 more serious injuries and, ultimately, one major accident or death. Interestingly, these numbers are similar to Heinrich’s, despite the criticism he received at the time. Although modern safety experts disagree with some of Heinrich’s, and even Bird’s, conclusions, both substantially advanced the idea that changing people’s behavior can prevent accidents.
More recently, Winston P. Ledet has linked the concept of plant reliability, or unreliability as the case may be, to operating and maintenance practices, more specifically to thousands of minor defects leading to additional repairs, thereby increasing the risk of loss (e.g., production, additional costs, etc.), and ultimately to major incidents, that is, lost time accidents, deaths and/or major production losses. This is shown pictorially in Figure 2.

This author’s own data and research from manufacturing plants support Ledet’s contention that the more defects you have, the higher the risk of injury, production losses, additional costs and environmental incidents.
Consistently found in numerous operations are:
- Overall equipment effectiveness (OEE) negatively correlated with injury rate, that is, the better a given operation runs, the lower the risk of injury.
- A reliable plant is a cost effective plant, that is, the better your operating and maintenance practices, the fewer the defects, thus the lower your costs will be.
- The greater your reactive maintenance, the higher the risk of injury. Conversely, the more planned and scheduled maintenance, the lower the risk of injury. Incidentally, OEE is also negatively correlated with reactive maintenance. The lower the reactive, the higher the OEE.
- Plants with higher OEE because of better operating and maintenance practices have fewer environmental releases.
These conclusions, along with the supporting data, are provided in the article, “Is Your Plant Reliable? It’s Good for Personal and Process Safety,” published in the February/March 2015 issue of Uptime magazine.
While all this may sound intuitively obvious, it’s comforting to know that the data from operating plants substantiate that a reliable plant is a safe plant, is a cost effective plant, and is an environmentally sound plant. Executives would be well served to take this into account in their decision-making, particularly when it comes to cutting maintenance costs and setting a high standard for operations and maintenance practices. Costs and injuries are a consequence of your practices.
Even more recently, Andrew Hopkins differentiates between personal safety and process safety. He contends that the two, while related and overlapping, are driven by different processes and thus require different approaches in minimizing risk. For example, he points out that so-called “slips, trips and falls” or injuries to individuals relate to personal behavior, which can be addressed through training, standards, personal protective equipment (PPE), etc. These incidents can be thought of as relatively high probability, low consequence. However, Hopkins also highlights that process errors increase the risk of major incidents – catastrophic failures – and result from poor operational discipline. Multilayered approaches and so-called safety nets minimize this risk, but the poorer the operational discipline, the greater the risk of a catastrophe. These can be thought of as relatively low probability, high consequence incidents. This is shown pictorially in Figures 3 and 4.


As shown in Figure 4, these issues influence each other, that is, defects and process errors can have a major impact on reliability, process safety and major incidents or accidents. Thus, the key to minimizing these is operational discipline throughout the organization in ALL practices.
As you can see, all these graphical models are pyramids, wherein the bottom layer increases the risk of the next greater impact above it until reaching the apex, which represents the worst case of the series of events. The theory, then, is if we can reduce the minor events in the bottom layer, we reduce the risk of major incidents; it’s a reasonable assumption. These models serve a good purpose and allow you to visualize the sequence and consequences, and take appropriate action to minimize the risk of major incidents. But, is there a better characterization?
James Reason first proposed the so-called Swiss cheese model around 1990, wherein risks are layered by practices and those practices have holes (e.g., omissions or poor practices), but only when the holes “line up” do the really bad things happen. Reason’s model was modified by Gordon Dupont of System Safety Services in Canada, as shown in Figure 5 (see page 54). The holes in the disks of “cheese” represent fallible decisions by senior management that lead to line management deficiencies. Combine them with preconditions, unsafe acts and inadequate safety nets and the result can be a major accident. However, it’s likely the holes are moving or changing on a regular basis and since all the holes must line up, it’s a statistical probability of uncertain magnitude, but one that increases with the number and size of the holes in each layer. Thus, one of management’s critical jobs is to minimize the size and number of holes in the organization’s systems by demanding and supporting excellence in all practices.

This article proposes an alternative model using the reliability process shown in Figures 6 and 7 (see page 54 and 55, respectfully). It is a blend of Ledet’s model – defects create problems and work orders, and the more work orders the greater the risk of losses and major incidents – and what this author calls the reliability process shown in Figure 6. In both models, organizations must eliminate the defects in their systems to improve performance. In the alternative model of Figure 7, each layer of “Swiss cheese” is made up of each element in the reliability process and the defects are the holes in the cheese induced by things like poor management and supervision, poor standards, poor training, poor implementation, and so on. The poorer these practices are, the greater the number of holes and, therefore, the risk of both minor and major events (e.g., a catastrophic accident, bankruptcy, etc.). Note, however, that industry experience and data from numerous operations indicate that there are typically more defects, or holes, in functions related to design, installation and start-up, and operation, than there are in maintenance, procurement, or stores.

Thus, the Swiss cheese version of this model might look something like Figure 7.

All the holes or defects in the system allow bad things to happen – injuries large and small, additional costs, lower output, poorer quality, poorer on time delivery, environmental incidents – and, ultimately, sometimes really big bad things, like catastrophes, deaths, or bankruptcies occur. More often than not, the initiating events are contained within the functional area and only lead to small bad things happening (e.g., an extra minor cost, a minor injury, a short disruption, etc.). Sometimes, they make it through to the next layer and the next. Also imagine that the holes are constantly changing, moving from one area to another within a function, or changing in size as people, managers, systems, standards, procedures, training and other things change. And finally, imagine that the discs are spinning round and round, driven by variability within each function. All this makes for a very complex system, but it’s only when the holes line up that really big bad things happen.
So the key to minimizing these events, both large and small, is to minimize the size and number of holes or defects in each functional area and to functionally align the goals and practices in all the areas so they work in concert, not conflict, to minimize that risk. These holes or defects typically relate to poor standards, training, procedures and, more broadly speaking and more accurately, to root cause, poor management and organizational culture, meaning a lack of operational discipline. W. Edwards Deming once said that 85 percent of all organizational problems are because of poor management. Just before he died, Deming said he was wrong, that it was 95 percent. Many agree with Deming.
Let’s look at a few examples of the defects in each functional area.
Designing for lowest installed cost vs. lowest lifecycle cost: This typically results in greater difficulty in operations and maintenance, and lower reliability and availability. Think of this approach as creating holes, or defects, in your design, increasing the risk of bad things happening in the system’s operation. Ease of operation and maintenance, along with high reliability and availability, should be at the forefront of any design.
Buying primarily based on price vs. the total cost of ownership: Likewise, this increases the risk of poor reliability and availability, and the inherent risk in operations and maintenance. Think of these poorer practices in procurement as adding holes or defects into the system.
Stores operation: Having a stores’ operation that is primarily focused on reducing inventory levels as opposed to balancing risk of loss, primarily production and maintenance efficiency, against working capital for a better system level effect also induces more holes in your system. This increases the probability of poorer performance and accidents. Likewise, having poor stores administrative and/or functional capability increases the risk of poor performance and accidents.
Installation/Start-up: One of the greatest risks to any operation is having poor installation and start-up practices. Huge holes occur in the system during this effort. For example, Rohm & Haas Company reported that you’re seven to 17 times more likely to introduce defects during start-up than normal operation; BP reported that incidents are 10 times more likely during start-up; the chemical industry reported process safety incidents are five times more likely during start-up; Paul Lucas, Principal Safety Consultant for ABB Ltd., reported that 56 percent of forced outages occur less than one week after a maintenance shutdown. All this is indicative of huge holes or defects in most organization’s installation and startup procedures, standards and practices. These must be addressed to reduce this risk.
Poor operating practices: They induce large numbers of holes or defects into systems not only in startup, but also in routine operation. Examples include not running the process or equipment per the standards, poor process conformance to standard operating conditions and procedures, having very loose standards that allow for excessive operational variation, inconsistency of operations across shifts, poor operator care, poor shift handover, etc. All these create holes or defects in the system, allowing for bad things to happen.
Poor maintenance practices: Examples include poor planning and scheduling, the inability to do proper planning and scheduling because of conflicts with operations or production planning, poor condition monitoring, inadequate preventive maintenance (e.g., too much, too little, or inexact standards), and workmanship (e.g., imprecise installation, poor alignment and balancing of machinery, etc.). It is the responsibility of senior management to understand and address all these shortcomings or defects in the organization’s practices. If you do all the little things right, the big bad things won’t happen.
No model is perfect in representing a given situation, particularly for complex systems, and these are just examples. Feel free to modify and adapt this to your circumstance.
As Deming suggested, underlying all these holes and defects in safety and reliability practices is primarily poor management and leadership that often lacks system-level thinking and creates a poor organizational culture. This results in poor operational discipline, leaving an abundance of holes in the layered Swiss cheese model and ample opportunity for bad things to happen, including poor operating results, high costs, poor quality, poor delivery performance and, of course, accidents, including catastrophic events.
All these defects in the practices must be addressed through senior management demanding and supporting operational excellence and discipline in all areas of the plant. They must put the systems and practices in place (e.g., policies, procedures, standards, checklists, etc.) to assure the defects covered in this article are addressed. They must also engage everyone, particularly the shop floor, in defect elimination. Performance measures, along with rewards (and even “punishment”) must reinforce these principles. Leaders must set the expectations and standards, and then drive operational excellence in their day-to-day actions.
