 "…Based on the famous Pareto principle, which states that 80 percent of the issues comes from 20 percent of the causes"
"…Based on the famous Pareto principle, which states that 80 percent of the issues comes from 20 percent of the causes"
Reliability engineering is about predicting failures and providing ground for decision-making related to preventive maintenance optimization (PMO), lifecycle costing, spare parts forecasting, and reliability, availability and maintainability (RAM) modeling. Different tools are available to the reliability engineer for such levels of predictions. The benefit of these tools comes from proper planning and management plans to cope with future issues.
The industrial environment, due to the nature of work, has a large variation in the use of such tools. One end of the industry is welcoming Industry 4.0, which is based on data analytics and machine learning algorithms. At the other end is an asset management framework to integrate already present tools. The strategic plans and objectives require the whole plant to be covered under one umbrella where different departments complement each other. The main purpose of the whole scheme is to prevent failures from happening. However, failures do happen and there is no guarantee you can stop failures 100 percent while remaining within appropriate budgetary constraints.
This reality check leads to the requirement of a program to deal with failure issues that exist in a plant even under the presence of reliability methodologies and strategies. Normally, it is called a bad actor program or performance killer. Both vary in nature, with one dealing with failures and the other with performance related issues. This article focuses on the development of a bad actor program and monitoring its effectiveness. However, the program can be applied similarly for performance killer.
Bad Actor Program
A bad actor program is designed to identify the gaps present in an organization’s current reliability strategies by analyzing unplanned failures based on the impact of each failure on maintenance cost and plant downtime. It is based on the famous Pareto principle, which states that 80 percent of the issues comes from 20 percent of the causes. By employing this principle, any organization can focus its attention on genuine and demanding issues related to plant maintenance and reliability, rather than overreacting on each failure.
The steps for a bad actor analysis are:
STEP 1: Define the scope of the plant-level analysis, either to consider the whole plant at a time or designated process areas of the plant individually for a selected time period.
STEP 2: Collect the work order history from the computerized maintenance management system (CMMS) for all assets.
STEP 3: Ensure the data in the work order consists of the equipment tag number, along with the order type, failure mode, cost of maintenance and associated downtime costs.
STEP 4: Use the collected data to prepare Pareto charts, so that equipment causing major failure costs ranks higher than others causing lower costs.
Table 1 - Ranking of Assets Based on Total Cost of Failure in Spreadsheet Format


Figure 1: Graphical form of a Pareto analysis of an asset
STEP 5: Select for further review the bad actors, which per the Pareto analysis would be the top 20 percent of assets.
STEP 6: Segregate the failure history of the selected assets for failure mode classification. Prepare the Pareto charts for failure modes existing in bad actors; the failure mode causing a frequent number of failures would rank higher than those causing fewer failures.
Table 2 - Ranking of Failure Based on Total Number of Failures in Spreadsheet Format


Figure 2: Graphical form of Pareto analysis of failure modes
STEP 7: Compare these failure modes against those present in the methodologies database. If the failure mode already exists, the recommendation should be reviewed and revalidated either to change the frequency or assign a new task. It is also necessary to revalidate or revise the maintenance procedure for each task reviewed.
STEP 8: Review and revalidate the failure mode as per your root cause analysis (RCA) approach if the failure mode does not exist in the strategy database. Revalidating the new failure mode in RCA should result in determining a suitable task for that failure mode, such as a new preventive maintenance (PM) task or a redesign of the equipment part.
STEP 9: Examine the outcome of the bad actor analysis, which should consist of PM amendments, additional PM tasks, redesign tasks, or others.

Figure 3: Workflow of bad actor program
Performance Evaluation
The bad actor program is a continuously evolving tool based on data collection. The data can be analyzed on a monthly basis, however, it requires accumulation of monthly data. The best practice for evaluating the program is a yearly review to accommodate the time needed to implement the recommendations.
Unlike other reliability studies, a bad actor program does not possess any particular key performance indicator (KPI). However, the process can be analyzed qualitatively. This is based on a comparison of current bad actors with those from the past year.
Figure 4: Illustration of bad actor performance
- If the past year’s recommendations were appropriate and executed properly as per standard operating procedures (SOPs), the bad actors should have moved off the bad actor list in the current bad actors analysis and replaced by others.
- It is also necessary to verify that the cost of failure for each previous bad actor in the current analysis is less than the cost of the previous year’s analysis.
- There should be no repetition of similar failure modes in consequent years for each past year bad actor. This means that equipment is susceptible to failure from other failure modes than those reviewed in the past year, but should not fail dominantly by previous failure modes.
If any of these issues exist, then the program should inspect the quality of different items, including the:
- Failure modes entry in work orders;
- Maintenance cost and downtime hours entry in work orders;
- Maintenance execution and procedures;
- Spare parts quality;
- Recommendations quality.
Upon completion of the inspection, coordination with the respective department(s) is necessary for addressing the issues.
 Figure 5: Workflow of bad actor evaluation
Figure 5: Workflow of bad actor evaluation
Conclusion
Failures are an undeniable part of plant maintenance. Failures happen irrespective of the strategies implemented for their prevention. However, with a better planning approach, these failures should be used to improve the state of the system. A bad actor program acts as a lagging KPI and should be used to remove gaps present in reliability strategies. If you don’t already have one, it’s time to develop your own bad actor program and evaluate its effectiveness.


 "…Based on the famous Pareto principle, which states that 80 percent of the issues comes from 20 percent of the causes"
"…Based on the famous Pareto principle, which states that 80 percent of the issues comes from 20 percent of the causes"
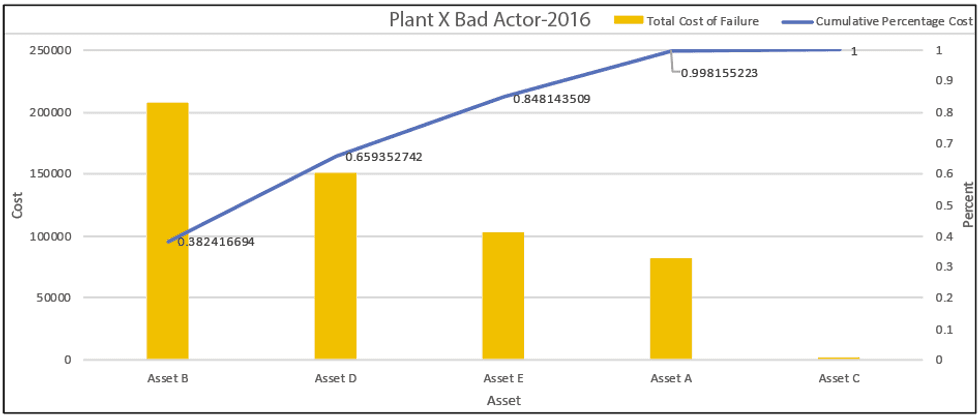
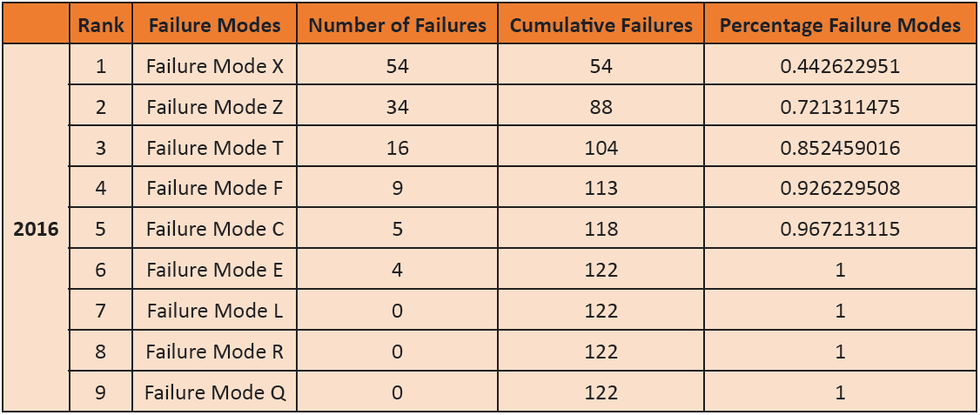
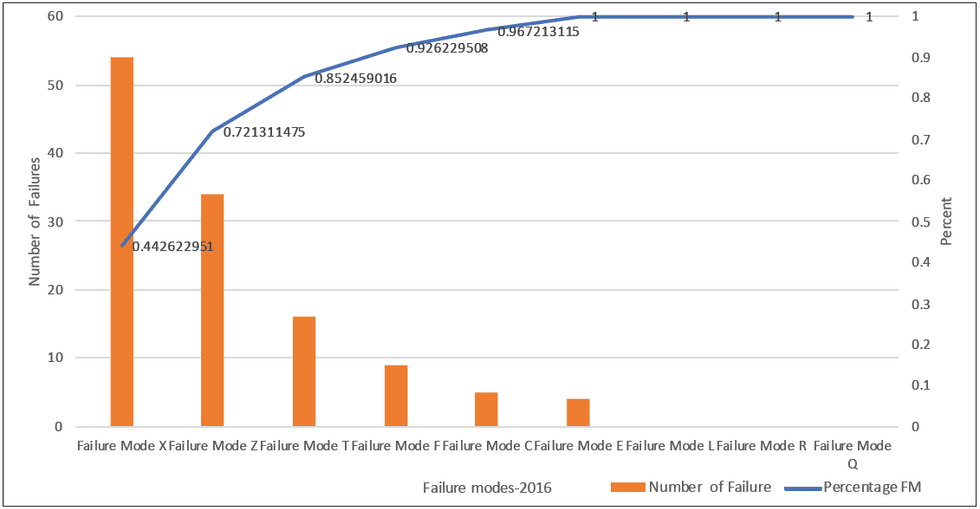

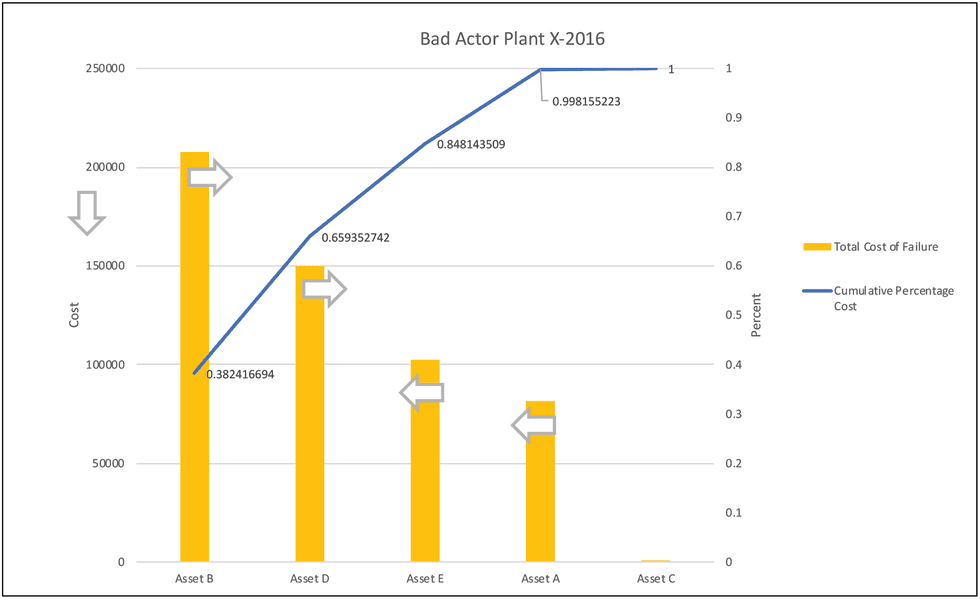
 Figure 5: Workflow of bad actor evaluation
Figure 5: Workflow of bad actor evaluation