Introduction
Recently, a member posed a question to other Society for Maintenance and Reliability Professionals (SMRP) members, prefacing the question with the fact that his management insisted on annual, mostly intrusive, maintenance, and based on the Original Equipment Manufacturer (OEM) recommendations, apparently with little or no exceptions. There are any number of problems with routinely and primarily applying a time-based
intrusive approach to maintenance. Let’s start with the basics. Figure 1 below illustrates the assumption for classic time-based intrusive maintenance, that works on the assumption that your equipment has a certain operating life, beyond which it goes into a wear-out zone. Therefore, you conduct intrusive maintenance—replacement, overhaul, repair—as the time approaches.
 Figure 1: Logic for time-based intrusive maintenance
Figure 1: Logic for time-based intrusive maintenance
Discussion
However, this logic is rarely applicable according to those who study equipment failure patterns. According to those studies, 1–3.5% of failures fit this time-based approach (see Figure 2, second graph down, and Figure 3, regarding RCM results for age-related and random failure patterns). Incidentally, the distinction between age-related and random failure patterns seems somewhat arbitrary, at least to me: They all have a random element and are all on a time frame, which can vary dramatically depending on the equipment and its operating context. For example, the infant mortality period for a transformer with a 40-year life might be one year, but for a bearing, it might be a few days. In any event, this characterization is common across studies.
 Figure 2: RCM—Age-related failure curves
Figure 2: RCM—Age-related failure curves
 Figure 3: RCM—Random failure curves
Figure 3: RCM—Random failure curves
The Navy data generally does not apply to industrial operations, mostly because the US Navy has exceptionally good operating and maintenance procedures executed in a disciplined way, compared to most industrial operations. They also have considerable sea-water corrosion-related failures, for which they have good databases for making decisions regarding time-based intrusive maintenance.
With data in mind, most components have a random failure pattern similar to Figure 4.
 Figure 4: Random failure pattern
Figure 4: Random failure pattern
The random failure pattern shown in Figure 4 is essentially a constant conditional probability of failure, indicated by a flat line in Figures 3 and 4. As such, 90% of equipment have a random failure pattern during their lives, either always, or after the infant mortality period, or before the wear-out period. The way we manage this random pattern is by using condition monitoring, both PdM and Operator Monitoring, and routine PM/inspections, applying the appropriate technique based on the equipment, its failure modes, and the consequence of failure. Once we have detected a pending failure, we plan and schedule the work to minimize its consequence to both maintenance and operations; it’s a joint effort. Moreover, we
must have exceptional installation, startup, and commissioning practices to reduce the risk in infant mortality failures (see Figure 4; some 67% of equipment exhibit this pattern). Time-based inspections (monitoring), lubes, filter changes, etc., are typically a good thing, but time-based intrusive maintenance is rarely good, unless you have consistent data to back it up, e.g., wear on a slurry pump impeller or brushes on a DC motor, corrosion on a sea water pump or valve, etc. These are wear- or corrosion-related failure modes, typically operated and maintained with precision practices and for which you have data. Note that high variation in practices creates high variation in defects and more random failures.
We have known this since WWII! Figure 5 below depicts the Waddington Effect, courtesy of Andrew Fraser, Reliable Manufacturing Ltd., regarding B-24 bomber maintenance. After every time-based major maintenance/overhauls (intrusive work), unscheduled maintenance for every 10 flight hours would spike (increasing downtime and reducing aircraft availability), then gradually decline until the next overhaul, then repeat the pattern. Doing time-based overhauls was detrimental to aircraft availability and mission capability. Likewise, doing so in a manufacturing plant without substantiating data would yield the same result.
 Figure 5: The Waddington Effect
Figure 5: The Waddington Effect
This conclusion was reinforced and articulated in greater detail by Nowlan and Heap in the 1960s, and later by John Moubray in his book
RCMII. The early problem in applying these principles was that PdM technology was not available, and when it was available, it was not easy. That’s all very different today.
Considering all this, below is the data on vendor PM recommendations from Steve Turner of OMCS International. My understanding is that he has other similar data. Vendor PMs tend to be biased by: 1) their strong desire to sell more by having you do more, and 2) their lack of understanding of your operating context, which can dramatically change the desired result. This is not to suggest that anyone should ignore vendor PM recommendations but rather, use them as a starting point and review them in light of any potential bias in the recommendations, along with your operating conditions.
 Figure 6: Vendor PM recommendations
Figure 6: Vendor PM recommendations
Moreover, lots of plant-developed PMs can be in need of substantial improvement. See Figure 6, Plant PM review results, courtesy of John Schultz, Allied Reliability.
 Figure 6: Plant PM review results
Figure 6: Plant PM review results
Finally, see Figure 7, Equipment availability vs. maintenance costs & strategies, courtesy of Roy Schuyler, then with DuPont, based on their operating plants. This figure demonstrates that the worst approach is one dominated by reactive maintenance, the next is time-based, even better is condition-based, and the best availability for a given cost is the combination of those three, plus adding a proactive element. Proactive work is focused on defect elimination. These defects are induced through less-than-stellar practices, most of which maintenance does NOT control, e.g., 1) design (failure to make the plant easy to operate, easy to maintain, and highly reliable), 2) procurement (focusing on initial cost vs. total cost of ownership), 3) stores (inadequate parts management), 4) installation and startup (see the infant mortality risk—several studies indicate that you’re five to ten times more likely to induce defects during startup than normal operation), 5) operation (poor startup, shutdown, and operating practices, variation in shift-to-shift practices), and, of course, 6) maintenance (insufficient precision in practices, tools and
training, etc.). If you eliminate the defects in your processes and equipment, you have fewer repairs and more time to conduct condition monitoring, inspections, planning and scheduling, and precision repairs. This results in longer equipment life, lower costs, and fewer injuries.
 Figure 7: Equipment availability vs. maintenance costs & strategies
Figure 7: Equipment availability vs. maintenance costs & strategies
All of this is confirmed by more data, shown in Figure 8, Maintenance costs vs. percent equipment on condition monitoring, and Figure 9, Maintenance costs vs. percent equipment on PM/time-based maintenance, again courtesy of John Schultz, derived from a study of 25 plants from five different companies. Based on this data, maintenance costs decline dramatically when using a condition-based approach and increase dramatically when using a time-based approach. There is a caveat to all this, that is, you must have excellent work management as well as planning and scheduling practices to act on the results of any condition monitoring, and you must also be proactive to eliminate the defects. If you stop the defects, you reduce the work and your costs. Regarding Figure 9, overdoing time-based intrusive maintenance when not necessary results in spending more time and money (and lost production) than necessary, and it restarts the risk of infant mortality failures. I personally observed this phenomenon at one large industrial operation when a contractor was hired as a replacement to veteran maintenance staff to “save on maintenance costs,” changing from a primarily condition-based approach to a time-based approach. In three months, maintenance costs doubled and uptime went down.
 Figure 8: Maintenance costs vs. percent equipment on condition monitoring
Figure 8: Maintenance costs vs. percent equipment on condition monitoring
 Figure 9: Maintenance costs vs. percent equipment on PM (time-based) maintenance
Figure 9: Maintenance costs vs. percent equipment on PM (time-based) maintenance
Other Observations
The above logic generally applies to all equipment. However, there may be exceptions. For example, if the P–F interval is very short (the period between potential failure—defect detected—and functional failure, when the system doesn’t meet requirements), you may want to adopt a different strategy for applying time- based maintenance and, as always, considering the consequence of failure. For example, the headlights on your car generally don’t give you any warning, but you have two headlights, so it’s acceptable to not change them periodically and let them run to failure. You might have a different approach if you’re going into the Australian Outback for several weeks, in which case, carrying a spare if driving at night is part of your mission.
On the other hand, your timing belt likely won’t give you any warning, and the consequence of failure can be catastrophic. So, doing a very conservative time-based maintenance, changing the belt based on miles or run-time, is likely the best approach. You’re probably over-maintaining relative to the average anticipated life of a belt—the belt will likely last far longer—but you can’t take that risk. Note that your installation practices still need to be superb!
Finally, one more example: Suppose you have PLCs in your plant, and it’s essential that they are 100% functional, 24/7, since the consequence of failure is huge. They aren’t likely to provide any warning of pending failure, and since the consequence is enormous, you will likely want to have an in-line spare, with both primary and secondary having function indicator lights. You’re encouraged to think of other appropriate time-based intrusive maintenance practices, such as those related to statutory requirements.
Conclusion
Just about everyone should conclude from all this that a primarily condition-based approach, especially when supplemented by a proactive, defect-elimination mindset, along with appropriate time-based maintenance, all based on data analysis, is far better than one that is primarily a time-based
intrusive approach. Of course, you can take a horse to the water, but you can’t make him drink.



 Figure 1: Logic for time-based intrusive maintenance
Figure 1: Logic for time-based intrusive maintenance  Figure 2: RCM—Age-related failure curves
Figure 2: RCM—Age-related failure curves  Figure 3: RCM—Random failure curves
Figure 3: RCM—Random failure curves  Figure 4: Random failure pattern
Figure 4: Random failure pattern  Figure 5: The Waddington Effect
Figure 5: The Waddington Effect  Figure 6: Vendor PM recommendations
Figure 6: Vendor PM recommendations 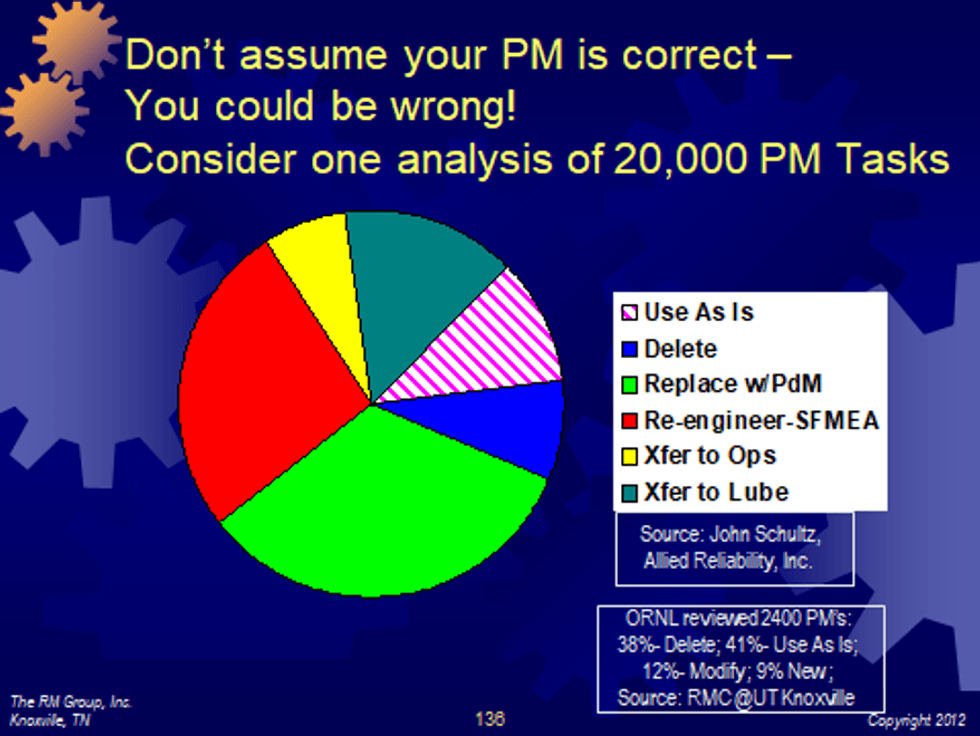 Figure 6: Plant PM review results
Figure 6: Plant PM review results  Figure 7: Equipment availability vs. maintenance costs & strategies
Figure 7: Equipment availability vs. maintenance costs & strategies  Figure 8: Maintenance costs vs. percent equipment on condition monitoring
Figure 8: Maintenance costs vs. percent equipment on condition monitoring  Figure 9: Maintenance costs vs. percent equipment on PM (time-based) maintenance
Figure 9: Maintenance costs vs. percent equipment on PM (time-based) maintenance 