by John Reeve
The short reason is because complex systems can have more requirements which, in turn, increase the number of failure points. And each requirement can have multiple prerequisites. An asset management system has three main areas needing ongoing attention: software/data, process/procedure and roles/responsibility. Advanced processes have the most prerequisites. Weakness in any one area or supporting variable can cause system failure.
System Failure Defined
From a maturity scale perspective, an asset management system failure could mean your system is simply below average. Symptoms within this category include poor data quality, lack of buy-in, inadequate user training, and/or minimal value-added reports. It could even mean your key performance indicators are poorly designed. In the case of absolute failure, a tipping point has been reached by the user community in that they no longer consider the system to be of any value. If a senior manager ever made comments like, "I don't see the value in this system. I can't get the reports I want. It costs too much," that should be a clue.
Let's Go Back in Time
With every implementation, there is an initial level of excitement. The leadership team has paid for the software and is now hoping to cash in on those benefits. Management is hoping to leverage data to make more informed decisions. The IT administration wants the newer technology to help them configure the system, load data and simplify integrations. Power users (e.g., planner/schedulers, maintenance supervisors) want to utilize the product to enhance workforce efficiency, generate ad hoc reports and automate key functions. And the working level simply wants to do their job and document failure history. They all want to do more with less effort. Bottom line: The system shouldn't make their job harder unless there is a benefit.
Decisions Are Needed
But will the decisions be the right ones? When setting up an asset management system, it is easier to make a wrong decision than a right one. Complex systems need expertise during the setup phase. You can ask the core team for requirements, goals and capabilities, but they might not always know what they want. They probably purchased a best of breed product because they sort of hoped it would give them flexibility once they determined what they really need to do. While it is true that you can easily configure the system, even after go live, some decisions are difficult to undo. Expertise is often needed to help a project team define the endgame, design analytical reports and develop a series of actions to get there.
Let's Talk About Failure History
As previously stated, the maintenance technician wants to record failure history on the work order. This is done for the benefit of the technician, so when the asset breaks again, he or she can quickly refer to prior events. It is good for the technician to record this text-based information (e.g., actions performed, problems discovered and failed component), but this is not actionable data. For those staff members who want to glean information from the asset management system in terms of recurring problems and worst offenders, they need to be able to execute structured query language (SQL) commands. Actionable data is validated data that enables analytical reports to quickly drill down and manage by exception. So depending on the person you talk to, there are two definitions of failure history, one that describes text-based information and one based on actionable data.
You Have a Short Window
Some say the working level decides within the first five minutes of being trained whether the system will be of any value to them. And once the system is live, the grumbling may start. If these issues are not heard, discussed and resolved by the core team, frustration can set in. In addition, if procedures for updating are not adhered to, the database can quickly become invalid. Lastly, if management is told the analytical reports can't be produced, the software might be perceived as problematic or weak.
CMMS Expert and Business Analyst Roles
A computerized maintenance management system (CMMS) expert is extensively familiar with work order management (e.g., work prioritization, work type categorization, backlog management and planning/scheduling), asset reliability (e.g., failure coding, failure analysis; failure mode, effects, and criticality analysis; and setting up a preventive maintenance/predictive maintenance program) and supply chain management. A CMMS expert is able to discuss all the above, regardless of software brand, and can discuss the industry in detail.
A business analyst schedules regular visits with the working level to ascertain problems, issues, complaints, needs and suggestions. The analyst may observe them using the system and will ask about report needs. A business analyst also identifies training issues or system network speed issues and may also perform short topic training. During the visit, the analyst may look for data stored outside the enterprise asset management (EAM) system, such as reports on a wall, spreadsheet applications, or paper files in cabinets. In general, the business analyst looks for early warnings of problems and issues.
Either of the above roles might be tasked with designing the analytical reports and building training materials. Plus, they may become involved with periodic benchmarking activities. Often, these two positions are recognized as positions of value within mature organizations.
Management Versus the Core Team
It's too easy to blame upper management for everything. In this regard, the core team should accept full responsibility of the asset management system. Management should authorize the software selection, provide budget dollars and approve decisions to integrate systems. But, the core team should be heavily involved in implementation and operation, including the CMMS's five-year plan. Periodic involvement by a steering team advocate may be needed to occasionally break through roadblocks. The core team needs a system to track enhancement requests, document CMMS changes, monitor change management issues via the business analyst and track training needs.
Typical Chronology
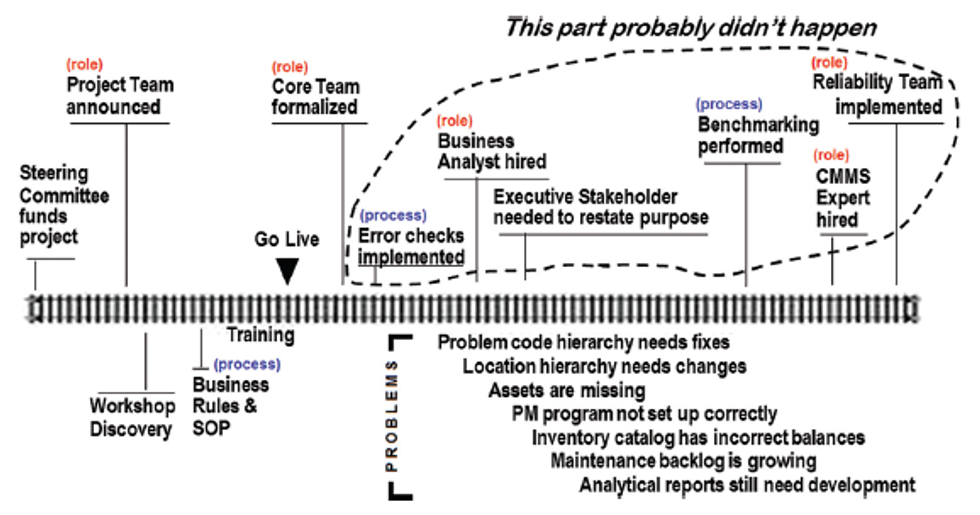
Figure 1 shows a series of events and problems that pop up after the implementation team disbands. Inside the dotted line are positions and roles that are often overlooked. Not every organization is able to pursue these roles, but remember, the subject of this article is, "Why Stuff Happens."

Staff Turnover and Tribal Knowledge
Every organization has employee turnover. This turnover could be within the maintenance trades, supervisors, or even the asset management stakeholders. Either way, this is a never-ending battle. In order to sustain excellence and optimize CMMS utilization, emphasis needs to be placed on creating a true knowledge base to store repair procedures (job plans), spare part lists, vendor contacts and failure history. Other more advanced techniques include repair/replace criteria, work order feedback, asset condition grading (as-left) and failed component identification, in addition to problem codes.
Analyzing Past Mistakes
Are you implementing software or an asset management system? Implementation teams frequently gravitate to software because the workshops may be weak when it comes to defining asset management concepts, purpose and definitions. Project teams may spend days discussing problem code hierarchies, but fail to identify the analytical report or who this report will be given to. Additionally, opportunities for improvement could be missed during the requirements phase.
One Should Not Assume Continuous Improvement Will Happen
Once the implementation team disbands and the consultants leave, there can be an enormous weight placed on the remaining staff. Perhaps foundation data is still missing (i.e., a job plan library). Or worse yet, maybe the reliability team is still studying the failure modes to determine ideal maintenance strategy (e.g., preventive maintenance, predictive maintenance, etc.). Maybe the procedures, such as completing a work order, are not finalized.
It is in these early months post go live that it is often discovered that the trades need more training. Perhaps they weren't quite clear after the four-hour training class. For some, it takes longer to catch on, but once they do, they become more involved, including asking for changes.
It should be noted that it may take a full year before an organization has settled into a comfortable routine.

How Do You Stop Bad Data
The core team should anticipate bad data at go live. It can and will happen. Therein, a prevention plan might be crafted to say:
1. Utilize validated fields. Activate mandatory features where applicable.
2. Identify a gatekeeper role to facilitate standardized reviews of incoming work.
3. Be sure the business rules are clear. Ask who is responsible for the accuracy of the work order record at job completion. Create a responsibility-accountability chart linking roles to asset management updates.
4. Identify pain points by the working level. Is it a training issue, data, or a system design change? Work closely with the maintenance organization. Understand its needs and concerns in terms of asset management interaction.
5. Conduct blended training that shows software and explains why this data is needed. This may be in the form of refresher training.
6. Set up error checks to proactively look for bad data. Even validated fields can have bad data.
7. Perform periodic process audits using a business analyst.
8. Conduct regular reviews of the maintenance backlog. Look for stale or duplicate work.
9. The core team should process change requests and issue tracking numbers to the requester in the form of a punch list.
10. Bad data could also mean missing data. Failure data as entry fields may be missing on the screen.
Different Groups Have Different Needs
Asset management systems do not run by themselves. The core team should be responsible for optimizing system value and meeting the needs of each stakeholder. The IT organization manages all software applications and integration therein. IT, however, should not be responsible for the data content or the surrounding processes.

Senior management should be extracting data using analytical reports to make better decisions. In support of continuous improvement, they should also develop and maintain a five-year plan. Without a road map in place, poor decisions could be made.
Stakeholders on the functional side, including the business analyst and CMMS expert, are responsible for understanding the current process and developing advanced processes. Without advanced processes in place, it is difficult to achieve a real return on investment (ROI).
Importance of a Core Team
The lack of a core team is usually the Number 1 indicator of a system in trouble. If an organization does not have a formal core team, then who will ensure fair representation of all the user groups? Who will fairly prioritize change requests? Who will document these changes? If you don't have a core team and are relying only on one person to manage the system, then you are putting the database at risk. Very seldom does a core team have a fully implemented vision at go live, but it is still the team's responsibility to keep that vision in view. The core team provides the glue that brings all the factions together.
You Don't Know What You Don't Know
The best advice for any organization implementing an asset management system is to closely monitor the data as it comes in for the first 12 months post go live. This strategy can help improve your knowledge of the system and users' needs. The second tip is to perform aggressive benchmarking. For example: What are other organizations doing for work scheduling? What techniques do they use to reduce reactive maintenance? How do they generate analytical reports? How do they track maintenance costs? How do you acquire best practice knowledge? Benchmarking can be done in several ways:
- Self-study, using books, magazines and online forums;
- Visiting other sites;
- Talking to other users, such as at user group conventions;
- Consultant services.
Don't Let This Happen to You
If senior leadership continually asks about meaningful reports, there could be a problem. If maintenance trades only see the asset management system as a time entry tool, there is a problem. If the backlog is mostly unplanned, poorly prioritized, or contains inaccurate statuses, there is a problem. Once the database becomes inaccurate, it becomes overwhelmingly impossible to recover. Thus, do you fix the data or the processes first? This is obviously a bad predicament to be in and most assuredly will reduce confidence in the system. And when the data goes bad, one of two things will happen:
- Leadership will say the product is not working and may suggest switching software.
- Leadership will request upgrade services and then tell the upgrade team not to bother migrating data.
Summary
So now that you know why stuff happens, don't let it happen to you. Ten to 15 years of entering work orders shouldn't be for naught. Similar to managing assets, anticipate problems and analyze what happened. Discover the real fault. A failure point could happen at any level in the organization, or any step in the process. And, there could be multiple points of failure. But with a strong asset management system, you can prevent, or at least be prepared, for when "stuff happens".




 John Reeve has over 25 years of diverse industry experience with expertise in work, asset and reliability managment system design. John demonstrates knowledge in business process reviews, influencing culture, 5-year plan creation and maintenance playbook development. He is a frequent speaker at user forums and author for industry trade magazines. John has a United States Patent 7421372 for maintenance scheduling involving unique "order of fire" routine in support of resource-leveling.
John Reeve has over 25 years of diverse industry experience with expertise in work, asset and reliability managment system design. John demonstrates knowledge in business process reviews, influencing culture, 5-year plan creation and maintenance playbook development. He is a frequent speaker at user forums and author for industry trade magazines. John has a United States Patent 7421372 for maintenance scheduling involving unique "order of fire" routine in support of resource-leveling.