PUBLISHER’S NOTE: I have spent close to 40 years learning and inquiring about various approaches to advance reliability and asset management. Although I have made a few of my own contributions, I treasure the contributions that come from others. In fact, the business I lead is optimized to provide opportunities for big contributors and small contributors alike. It includes book publishing, magazine and website publishing, conference presentations, training workshops, roundtable discussions, keynote addresses, white papers, research reports, project guides, videos, podcasts, webinars, and all other forms of modern communication. I get great satisfaction providing a stage and platform for people to express their work, especially when it can be used to make the people we serve safer and more successful by advancing reliability and asset management. - Terrence O'Hanlon
The objective for this article is to redefine Asset Performance Management (APM) and its maturity levels in a way that will make more sense to the asset owner, the technology company stakeholders and, hopefully, some the analysts who originally defined APM themselves.
World According to Reliability
If you work for an asset intensive organization and your role involves ensuring value from assets, you are unlikely to organize the world by software applications as software marketing professionals or software analysts’ do in order to describe these applications and functions to chief information officers, IT leaders or other chief officers.
As a reliability leader, you begin with a theory of reliability, which, in simple terms, is about a failure-free operation. Leading businesses and mission focused organizations also include a theory of asset management, which, in simple terms, is coordinating activities across the functional roles in the organization and across the asset’s lifecycle and across the enterprise to ensure value is delivered from the assets. A reliability and asset management strategy will usually include a comprehensive collection of technically valid and economically feasible maintenance tasks, including condition-directed tasks, time-directed tasks, failure finding tasks and run to failure decisions packaged as a preventive maintenance program.
Preventive maintenance explained simply is asset servicing (e.g., repair, renew, replace) and inspection that is part of your plan and strategy. In other words, you know you are going to do it.
Corrective maintenance explained simply is asset servicing (e.g., repair, renew, replace) that surprises you – it is not part of your plan or strategy. In other words, it is an asset failure you did not have covered by a reliability strategy or there is a flaw in the reliability strategy you had for it.
It would be great if all assets were maintenance free and failure free, but that is an aspiration one may need to wait for Industry 5.0 to deliver as, to my knowledge, it is not an objective for Industry 4.0.
In the interim, most industrial organizations use maintenance work management applications, such as computerized maintenance management systems (CMMS) or enterprise asset management (EAM), to manage their preventive maintenance program and the corrective work management program created from reliability strategy development or other sources. These applications create work orders, store equipment maintenance history (e.g., schedules, failures, repairs, inspection results, material and parts usage, root causes, job plans, bill of materials, observations and notes, other data) and asset data.
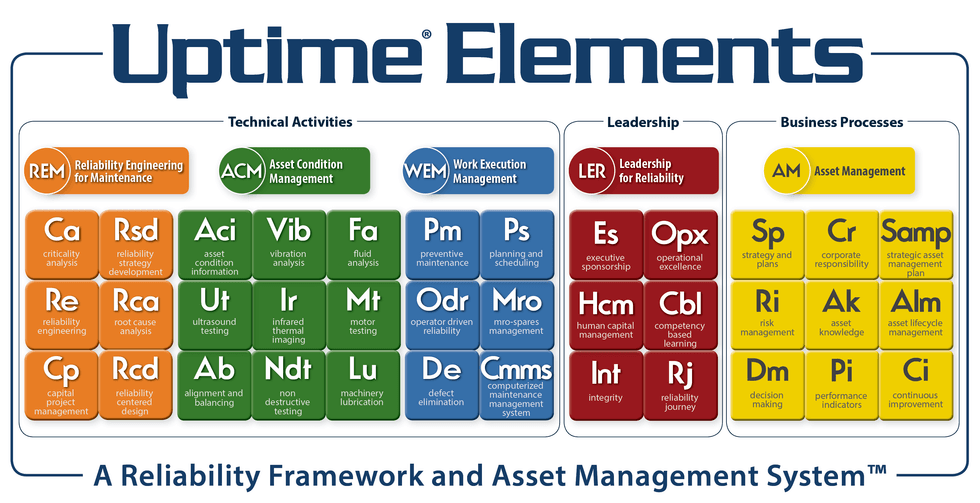
You need a basic understanding of two reliability concepts in order to gain insight into how asset performance management works in a holistic system or reliability framework, as shown in Figure 1. One is reliability strategy development using the failure patterns. The other is asset condition management.

Figure 1: Uptime Elements A Reliability Framework and Asset Management System
Reliability Strategy Development
As previously stated, asset intensive organizations use CMMS/EAM applications to manage preventive maintenance programs created from reliability strategy development or other sources. As renowned fiction writer, William Shakespeare stated, “Ay, there’s the rub!”
According to the Uptime
® Elements – A Reliability Framework and Asset Management System™ body of knowledge, reliability strategy development uses tools like, reliability-centered maintenance (RCM), preventive maintenance optimization (PMO), and failure mode and effects analysis (FMEA)/failure mode, effects and criticality analysis (FMECA), to identify failure modes/failure mechanisms and failure causes, then applies a technical sound and economically feasible maintenance task to eliminate the functional failure.
But, what about the other sources? Typically, the other sources for maintenance tasks are:
- Original equipment manufacturers (OEM);
- “We’ve always done it that way!”
- Universal knee-jerk reaction to last data point management PM;
- “No one knows why we do this one.”
Although it is possible that some of these maintenance tasks are adding value and contributing to reliability, it is more likely they are not. They may actually be causing your assets harm.
Only maintenance tasks that are technically validated should be performed since there is a high probability that laying hands on or invading the boundary of a perfectly good working asset will create what is known as infant mortality or a worse new or worse repaired condition, as shown in Figure 2.
 Reliabilityweb.com
Reliabilityweb.com
Figure 2: Risk of performing intrusive, time directed tasks
Maintenance tasks should be based on technically and economically effective responses to failure modes that can defeat the function of an asset or system. Since most failure patterns are random (i.e., not related to time), the most appropriate maintenance task decisions will usually be condition directed tasks or no maintenance task at all as a run to failure decision. Run to failure decisions must be integrated into any preventive maintenance program because many of your assets and systems do not justify time directed or condition directed preventive tasks. For example, a standard light bulb runs to failure, an employee reports it, and a replacement is scheduled.
Assets require some sort of intervention in the form of maintenance because of excessive age (usually less than five percent) or basic wear and tear (less than 12 percent). You may be able to make an argument, depending on the type of assets your organization operates, that basic wear and tear could extend to 23 percent (see failure patterns in Figure 3), but you rarely see it extend much higher. Aging assets arguments are handled on a case-by-case basis, depending on your organization’s appetite for capital investment.
That still leaves a gaping 75 percent of asset failures caused by the asset not getting all the care it needs to run perfectly. Some reasons for those failures include:
- The defects preventing value and causing failure could have been created in the design stage of the asset’s life and without redesign is not something maintenance is going to improve.
- The defects preventing value and causing failure could have been created in the build or asset creation phase.
- The defects preventing value and causing failure could have been created in the commissioning or installation phase.
- The defects preventing value and causing failure could be caused by raw material input or process inputs.
- The defects preventing value and causing failure could be caused by operational discipline issues.
- The defects preventing value and causing failure could be caused by maintenance workmanship.
- The defects preventing value and causing failure could be caused by maintenance material.The defects preventing value and causing failure could be caused by raw material input or process inputs.
- The defects preventing value and causing failure could be caused by data deficiency or poor information management.
- The defects preventing value and causing failure could be caused by senior management policy.
As an asset owner, you want your assets to deliver the organizational objectives (i.e., value) and you want to remove as much uncertainty (i.e., risk) as needed to do so. It’s about having the ability to manage asset performance (i.e., APM) by automating condition monitoring, inspection results, operating data and other observations and conditions, setting rules, possibly adding machine learning (ML) and artificial intelligence (AI), and feeding the results and requested follow-up actions to the work management system (CMMS/EAM). The feedback loop then monitors the effectiveness and efficiency of the task to optimize future task decisions.
Asset Condition Management
Asset condition management (ACM) involves measuring and monitoring equipment condition, system trends and operational performance using selected operating parameters and techniques to forecast the potential for future failures and permit timely maintenance in advance of these failures.
Modern condition monitoring technology provides information that can be confidently used to operate at maximum capacity and efficiency for a given load or throughput, as well as to scope and schedule emergent/secondary maintenance tasks based on asset condition. This monitoring capability also contributes to reliability and safety by ensuring that impending potential failures are identified and corrected at an early stage, minimizing both cost and the potential for catastrophic failure.

Figure 3: The D-I-P-F curve and failure patterns
ACM often provides maintenance personnel with the ability to assess the operating condition of equipment at any time and permit the monitoring of progressive deterioration of components without the necessity for their physical inspection through intrusive inspection.
Condition monitoring provides useful information to diagnose and correct problems early in the aging or failure sequence. This permits maintenance to be planned and scheduled with minimal impact on plant operation.
ACM is generally nonintrusive and does not interfere with equipment control functions or instrumentation.
The Gravity Trap of the Maintenance Maturity Domains
Conventional best practices wisdom promoted by traditional old-school maintenance experts guide you from the reactive domain to the preventive maintenance or planned maintenance domain. From there, they guide you to the predictive maintenance domain, then the reliability-centered maintenance domain and finally the newly minted Internet of Things-enabled prescriptive maintenance domain.
 Uptime Elements Digitalization Strategy Framework
reliabilityweb.com
Uptime Elements Digitalization Strategy Framework
reliabilityweb.com
Figure 4: Uptime Elements Internet of Things Knowledge Domain
If reliability and asset performance are your objectives, here’s the bad news: The best practices for maintenance do not work. In fact, they never did! The planned maintenance domain is not stable.
The Terrence O’Hanlon’s Laws state:
- You cannot maintain your way to reliability and asset performance.
- You cannot preventive maintenance your way to reliability and asset performance.
- You cannot predictive maintenance your way to reliability and asset performance.
- You cannot reliability-centered maintenance your way to reliability and asset performance.
- You cannot prescriptive maintenance your way to reliability and asset performance.
The maturity journey to reliability and asset management is one of people/culture, practices/processes and technologies and will likely stretch across several domains.
Table 1: Uptime Elements Asset Performance Management Maturity Matrix

Table 2: Five Disciplines of a High Reliability Organization

The
maintenance concept has become so mistakenly entwined with reliability that the two terms are often used as synonyms. No CEO wants more maintenance – think “high maintenance.” All CEOs want failure-free operations – think “high reliability. Which would you rather be?
 High Maintenance or High Reliability?Terrence O'Hanlon and Jeff Smith
High Maintenance or High Reliability?Terrence O'Hanlon and Jeff Smith
 The planned domain is not a stable domain because without a high reliability culture, it is likely that everyone across the organization is adding defects into the system faster than the maintenance and inspection system can remove them. Set the next destination for the precision domain and realize that parts of your strategy and maturity will stretch across multiple domains.
The planned domain is not a stable domain because without a high reliability culture, it is likely that everyone across the organization is adding defects into the system faster than the maintenance and inspection system can remove them. Set the next destination for the precision domain and realize that parts of your strategy and maturity will stretch across multiple domains.
As a reliability leader, your role is to point the way to
world class and set the ultimate destination to being a “learning organization” that has flexibility through the use of a framework for future reliability and asset management challenges.
Encourage yourself to learn more about ISO55000/55001/55002, Managing System for Asset Management, Uptime Elements – A Reliability Framework and Asset Management System and Uptime Elements Digitalization Strategy Framework to lead the way toward creating a cross-functional, engaged and empowered team of reliability leaders across your enterprise who stand for delivering a safe, sustainable, failure-free value toward organizational objectives from assets.
 Uptime Elements as an ISO 55001 Asset Management System
Terrence O'Hanlon
Uptime Elements as an ISO 55001 Asset Management System
Terrence O'Hanlon
Today, there are numerous technology providers that offer platforms for asset performance management fueling EAM. Begin your advance with a strategic view toward the people side of the journey, which is usually the most significant and difficult, the process side of the journey and the technology side of the journey.
A dynamic linkage and feedback loops between reliability strategy management, asset condition management and EAM will fuel asset performance and delivery of organizational objectives in a safe and sustainable fashion.
Below is a 30 minute video of a 30 minute presentation I gave with the same title. I hope you will watch and listen and then send me your comments or start a discussion at LinkedIn.
Thank you for your time and energy.
From Your Site Articles
Related Articles Around the Web



 Reliabilityweb.com
Reliabilityweb.com
 Uptime Elements Digitalization Strategy Framework
reliabilityweb.com
Uptime Elements Digitalization Strategy Framework
reliabilityweb.com


 High Maintenance or High Reliability?Terrence O'Hanlon and Jeff Smith
High Maintenance or High Reliability?Terrence O'Hanlon and Jeff Smith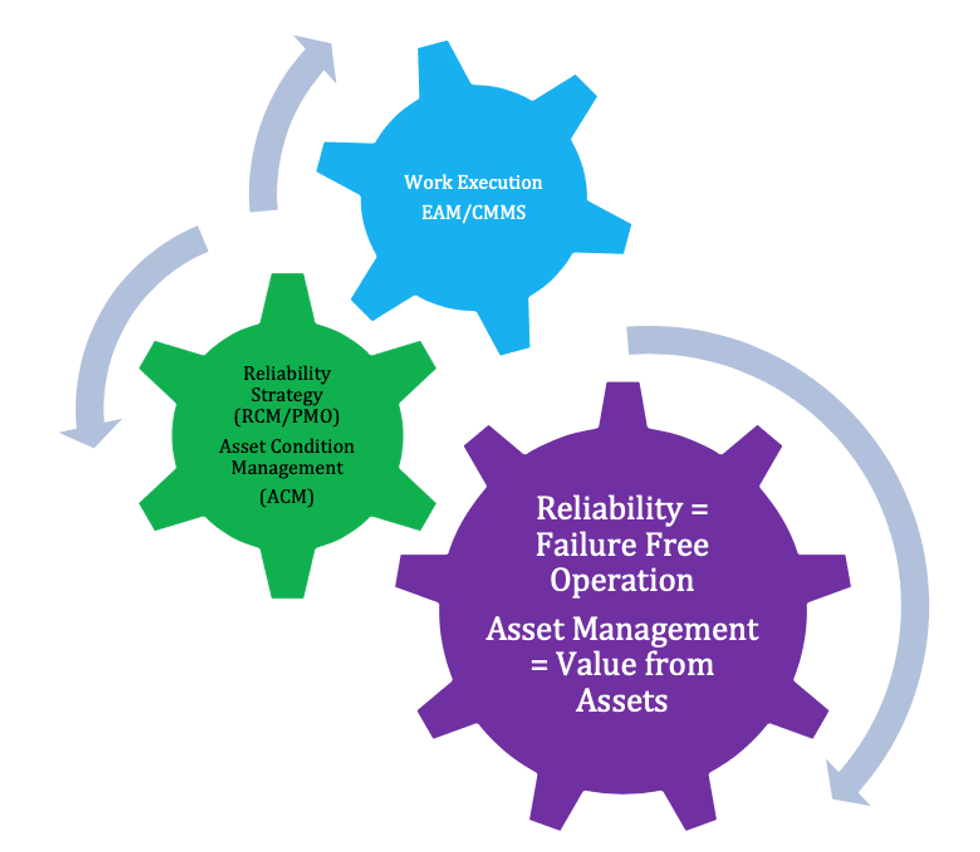 The planned domain is not a stable domain because without a high reliability culture, it is likely that everyone across the organization is adding defects into the system faster than the maintenance and inspection system can remove them. Set the next destination for the precision domain and realize that parts of your strategy and maturity will stretch across multiple domains.
The planned domain is not a stable domain because without a high reliability culture, it is likely that everyone across the organization is adding defects into the system faster than the maintenance and inspection system can remove them. Set the next destination for the precision domain and realize that parts of your strategy and maturity will stretch across multiple domains.
 Uptime Elements as an ISO 55001 Asset Management System
Terrence O'Hanlon
Uptime Elements as an ISO 55001 Asset Management System
Terrence O'Hanlon
